How ChatGPT works?


How ChatGPT Works — Step by Step
🔹 A. Training Phase (Before You Ever Use It)
ChatGPT is trained in two major steps:
Step 1: Pretraining
- Input: Billions of sentences from websites, books, Wikipedia, conversations, etc.
- Goal: Predict the next word in a sentence.
- It learns grammar, facts, reasoning patterns, even some logic.
Example:
Input: "The capital of France is"
The model learns that the likely next word is “Paris”.
This is done unsupervised — it learns from raw text using transformer-based neural networks.
🧠 Neural Network Structure:
Imagine a neural network as a grid of neurons (like brain cells) with connections (weights) between them. The transformer model looks like this:
Input Sentence → [Embedding Layer] → [Transformer Blocks × N] → [Output Layer]
Each Transformer Block contains:
- Multi-head Self-Attention (focus on important words)
- Feed-forward layers
- Normalization and residual connections
Let’s visualize a simplified diagram:
[Input Text]
↓
[Tokenizer]
↓
[Word Embeddings]
↓
[Transformer Layers] -- (Self-Attention, FFN)
↓
[Output Probabilities]
↓
[Next Word Prediction]
The Self-Attention mechanism helps the model understand context, e.g., in:
"He fed the dog because it was hungry", it figures out that "it" refers to "dog".
Step 2: Fine-Tuning (ChatGPT Phase)
OpenAI fine-tunes the base GPT model using human feedback:
- People ask questions.
- They rate the answers.
- The model is reinforced to give more helpful, safe, and correct responses.
This is called Reinforcement Learning from Human Feedback (RLHF).
🔹 B. Inference Phase (When You Chat With It)
When you type:
“Write a poem about mountains”
Here’s what happens:
- Tokenization
Breaks your input into tokens (words/pieces of words). - Context Understanding
It processes your tokens using Transformer blocks with self-attention to understand the structure. - Prediction Loop
It predicts the next token, then the next, until it finishes the output. - Output Generation
It stitches tokens together to form readable text.
💡 Real Example: You ask —
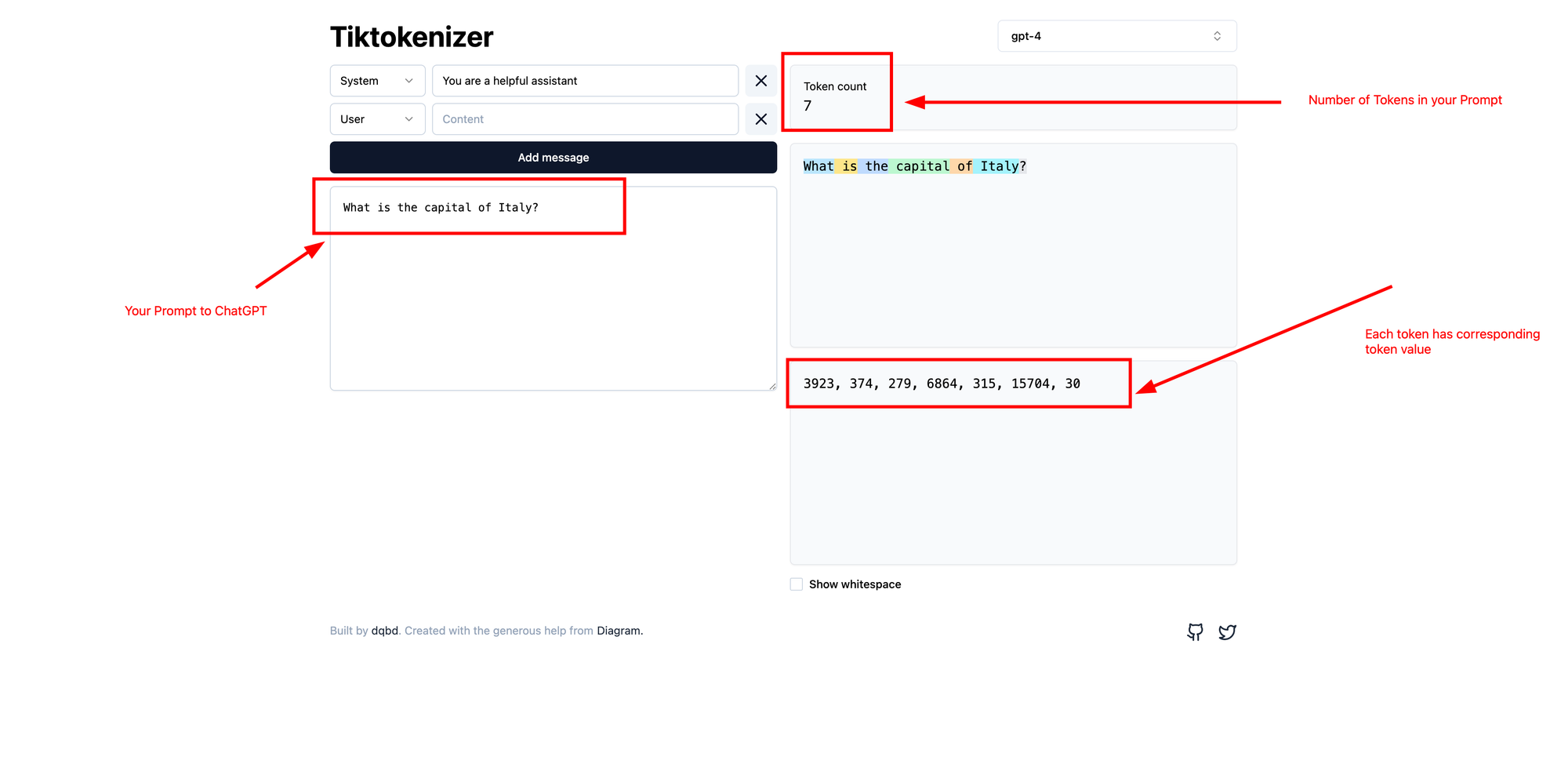
"What is the capital of Italy?"
- Input Tokens:
- "What", "is", "the", "capital", "of", "Italy", "?" ( use this platform to find number of token in your input --> https://tiktokenizer.vercel.app/?model=gpt-4
- Self-Attention:
- The model sees "Italy" and learns it’s the focus.
- Prediction:
- It predicts next token to be "Rome".
- Output:
- "The capital of Italy is Rome."
🔍 How ChatGPT Reaches a Conclusion
- Pattern Matching
It has seen thousands of sentences like:
"Capital of X is Y" → learns the pattern. - Context Awareness
It pays attention to all parts of the sentence using self-attention. - Probabilistic Output
It doesn't memorize, it generates based on probability of correct answer. - No Real-Time Web Access (unless connected to tools):
It knows things only up to training cut-off (e.g., Jan 2025 knowledge).
🔁 Summary
| Component | Role |
|---|---|
| Tokenizer | Breaks words into smaller units |
| Embeddings | Converts tokens into vectors |
| Transformer Layers | Understand context & relations |
| Attention Mechanism | Focuses on important words |
| Output Layer | Predicts the next word |
| Training Data | Provides knowledge & patterns |
| RLHF | Aligns with human preferences |



